
Bonne lecture 
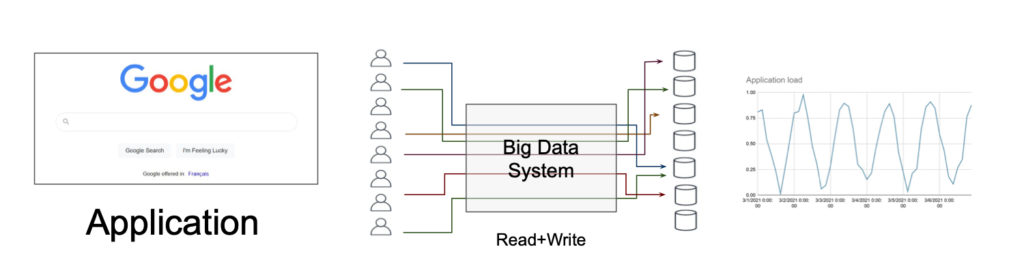
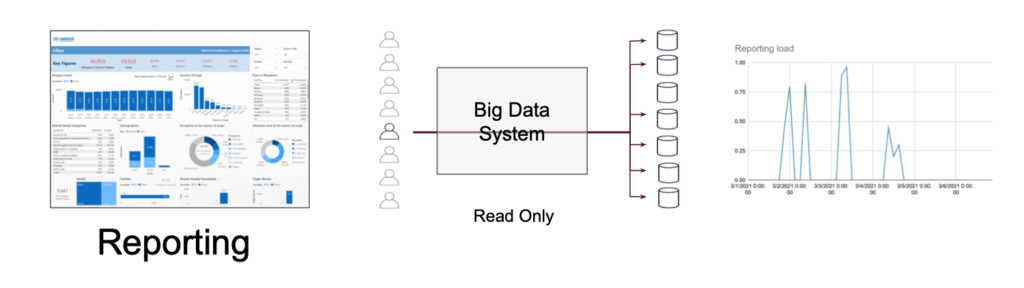

En route vers l’automatisation : iceberg, procrastination et nœud gordien
Quels sont les freins et accélérateurs du DevOps ? Iceberg Lorsque l’on évoque l’automatisation, le top management dispose trop souvent de peu d’indicateurs sur le volume de....

Cas d’usage DataOps: Industrialisation des environnements et processus...
Voici un exemple de travail réalisé par un des membres de notre communauté dans une des plus grandes entreprises françaises, pour industrialiser l’environnement de travail, l’accès et le traitement...
SEO vocal et monétisation des applications vocales
Les assistants vocaux s’inscrivent dans les enjeux du marketing digital mais les règles et techniques du web et des applications mobiles ne s’appliquent plus. Il est nécessaire de penser un positionnement...